前期工作
1、跟新升级软件包
1
2
| sudo apt-get update
sudo apt-get yum upgrade
|
2、创建hadoop用户
1
2
3
| adduser hadoop
passwd hadoop
|
修改文件/etc/sudoers 在root ALL=(ALL) ALL 下添加一行
进入hadoop用户
3、关闭防火墙
1
2
| sudo apt-get install ufw
sudo ufw disable
|
4、设置主机名(可自行设置,设置之后hadoop相关配置项需要跟着改动)
1
| hostnamectl set-hostname node1
|
5、下载 JDK
在这之前建议可以将 /usr 目录设置为公开目录
6、需要注意一下配置ssh免密登陆
如果以前配置过则先删除以前的免密登陆:
然后配置免密登陆:
1
2
3
4
| cd ~/.ssh
ssh-keygen -t rsa #一路回车
cat id_rsa.pub >> authorized_keys
chmod 600 authorized_keys
|
如果没有配置过,则直接下载ssh
1
2
| sudo apt install openssh-server
sudo service ssh start
|
配置免密登陆
1
2
3
4
| ssh-keygen -t rsa
cd ~/.ssh
cat id_rsa.pub >> authorized_keys
chmod 600 authorized_keys
|
此时执行 ssh localhost 没有问题则证明可以了 ctrl + d 退出
JDK 安装
1、新建JDK文件夹
1
| sudo mkdir /usr/local/java
|
2、将在官网下载JDK,并解压
1
| tar zxvf jdk-8u221-linux-x64.tar.gz -C /usr/local/java
|
配置 JAVA_HOME 环境变量
在文件里面添加以下配置
1
2
3
4
| export JAVA_HOME=/usr/local/java/jdk1.8.0_221
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
|
执行如下命令使其生效
测试执行 echo $JAVA_HOME 正确打印出路径就配置成功了
Zookeeper 安装
1、创建 Zookeeper 工作路径
1
2
| mkdir -p /usr/zookeeper
cd /usr/zookeeper
|
2、下载zookeeper
1
| wget http://archive.apache.org/dist/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz
|
3、解压
1
| tar -zxvf /usr/zookeeper/zookeeper-3.4.10.tar.gz -C /usr/zookeeper
|
4、删除软件包
1
| rm -rf /usr/zookeeper/zookeeper-3.4.10.tar.gz
|
5、创建配置中所需的zkdata和zkdatalog两个文件夹
1
2
3
| cd /usr/zookeeper/zookeeper-3.4.10
mkdir zkdata_1 zkdata_2 zkdata_3
mkdir zkdatalog_1 zkdatalog_2 zkdatalog_3
|
6、配置文件zoo.cfg,将zoo_sample.cfg文件拷贝一份命名为zoo.cfg,Zookeeper 在启动时会找这个文件作为默认配置文件。
1
2
3
4
| cd /usr/zookeeper/zookeeper-3.4.10/conf/
cp zoo_sample.cfg zoo1.cfg
cp zoo_sample.cfg zoo2.cfg
cp zoo_sample.cfg zoo3.cfg
|
zoo1.cfg内容如下:
1
2
3
4
5
6
7
8
9
| tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/zookeeper/zookeeper-3.4.10/zkdata_1
clientPort=2181
dataLogDir=/usr/zookeeper/zookeeper-3.4.10/zkdatalog_1
server.1=localhost:2887:3887
server.2=localhost:2888:3888
server.3=localhost:2889:3889
|
zoo2.cfg内容如下:
1
2
3
4
5
6
7
8
9
| tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/zookeeper/zookeeper-3.4.10/zkdata_2
clientPort=2183
dataLogDir=/usr/zookeeper/zookeeper-3.4.10/zkdatalog_2
server.1=localhost:2887:3887
server.2=localhost:2888:3888
server.3=localhost:2889:3889
|
zoo3.cfg内容如下:
1
2
3
4
5
6
7
8
9
| tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/zookeeper/zookeeper-3.4.10/zkdata_3
clientPort=2183
dataLogDir=/usr/zookeeper/zookeeper-3.4.10/zkdatalog_3
server.1=localhost:2887:3887
server.2=localhost:2888:3888
server.3=localhost:2889:3889
|
7、创建文件myid
1
2
3
| echo "1" > /usr/zookeeper/zookeeper-3.4.10/zkdata_1/myid
echo "2" > /usr/zookeeper/zookeeper-3.4.10/zkdata_2/myid
echo "3" > /usr/zookeeper/zookeeper-3.4.10/zkdata_3/myid
|
8、配置 Zookeeper 环境变量
输入以下内容
1
2
| export ZOOKEEPER_HOME=/usr/zookeeper/zookeeper-3.4.10
PATH=$PATH:$ZOOKEEPER_HOME/bin
|
激活环境变量
开启 Zookeeper 服务:
1
2
3
| /usr/zookeeper/zookeeper-3.4.10/bin/zkServer.sh start zoo1.cfg
/usr/zookeeper/zookeeper-3.4.10/bin/zkServer.sh start zoo2.cfg
/usr/zookeeper/zookeeper-3.4.10/bin/zkServer.sh start zoo3.cfg
|
查看是否启动成功:
1
2
3
4
5
| [root@node1 ~]# jps
14496 Jps
13282 QuorumPeerMain
13255 QuorumPeerMain
13323 QuorumPeerMain
|
Hadoop 安装
1、创建 hadoop 的工作路径
1
2
| mkdir -p /usr/hadoop
cd /usr/hadoop
|
2、下载 Hadoop
1
| wget https://archive.apache.org/dist/hadoop/core/hadoop-2.7.3/hadoop-2.7.3.tar.gz
|
3、解压到 /usr/hadoop
1
| tar -zxvf hadoop-2.7.3.tar.gz -C /usr/hadoop/
|
4、删除软件包
1
| rm -rf /usr/hadoop/hadoop-2.7.3.tar.gz
|
5、配置环境变量
添加如下内容:
1
2
3
| export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export CLASSPATH=$CLASSPATH:$HADOOP_HOME/lib
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
|
激活环境变量:
6、测试 Hadoop
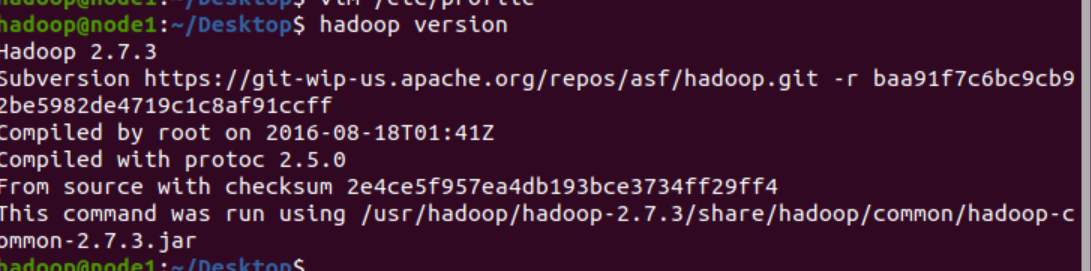
7、配置 Hadoop 组件
1)hadoop-env.sh环境配置文件
1
2
| cd $HADOOP_HOME/etc/hadoop
vim hadoop-env.sh
|
添加如下内容
1
| JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
|
2)core-site.xml文件
添加如下内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| <property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://node1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoop-2.7.3/hdfs/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>fs.checkpoint.period</name>
<value>60</value>
</property>
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
</property>
|
3)hdfs-site.xml文件
添加如下内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| <property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/hadoop-2.7.3/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/hadoop-2.7.3/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
|
4)yarn-site.xml文件
添加如下文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
<property>
<name>yarn.resourcemanager.address</name>
<value>node1:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>node1:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>node1:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>node1:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>node1:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
|
5)mapred-site.xml文件
1
2
| cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
|
添加如下内容:
1
2
3
4
5
| <property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
|
8、hadoop名称节点初始化
当没报错并出现“Exiting with status 0”的时候,表明格式化成功。
9、开启 Hadoop
1
2
| cd /usr/hadoop/hadoop-2.7.3/sbin
./start-all.sh
|
10、查看是否启动成功:
1
2
3
4
5
6
7
8
9
10
| [root@node1 hadoop-2.7.3/sbin]# jps
15552 NameNode
16129 Jps
13282 QuorumPeerMain
15670 DataNode
15174 ResourceManager
13255 QuorumPeerMain
13323 QuorumPeerMain
16029 NodeManager
15822 SecondaryNameNode
|
Hbase 安装
1、创建hbase的工作路径
1
2
| mkdir -p /usr/hbase
cd /usr/hbase
|
2、下载hbase
1
| wget https://archive.apache.org/dist/hbase/1.2.4/hbase-1.2.4-bin.tar.gz
|
3、解压到/usr/hbase
1
| tar -zxvf hbase-1.2.4-bin.tar.gz -C /usr/hbase
|
4、删除软件包
1
| rm -rf /usr/hbase/hbase-1.2.4-bin.tar.gz
|
5、配置hbase-env.sh
1
2
| cd /usr/hbase/hbase-1.2.4/conf
vim hbase-env.sh
|
添加如下内容:
1
2
3
| export HBASE_MANAGES_ZK=false
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HBASE_CLASSPATH=/usr/hadoop/hadoop-2.7.3/etc/hadoop
|
6、配置 hbase-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| <property>
<name>hbase.rootdir</name>
<value>hdfs://node1:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.bigdata</name>
<value>hdfs://bigdata:6000</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/zookeeper/zookeeper-3.4.10</value>
</property>
|
7、hadoop 配置文件拷入
1
2
| cp /usr/hadoop/hadoop-2.7.3/etc/hadoop/hdfs-site.xml /usr/hbase/hbase-1.2.4/conf
cp /usr/hadoop/hadoop-2.7.3/etc/hadoop/core-site.xml /usr/hbase/hbase-1.2.4/conf
|
8、配置环境变量
9、添加如下内容:
1
2
| export HBASE_HOME=/usr/hbase/hbase-1.2.4
export PATH=$PATH:$HBASE_HOME/bin
|
10、激活环境变量:
11、启动 HBase
12、查看是否启动成功:
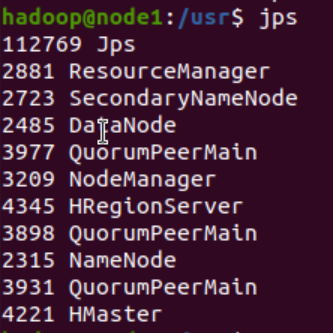
启动命令
1、切换用户
su hadoop
密码:hadoop
2、启动Zookeeper
cd /usr/zookeeper/zookeeper-3.4.10/bin/
zkServer.sh start zoo1.cfg
zkServer.sh start zoo2.cfg
zkServer.sh start zoo3.cfg
4、启动hadoop
cd /usr/hadoop/hadoop-2.7.3/sbin
./start-all.sh
5、启动hbase
cd /usr/hbase/hbase-1.2.4/bin
./start-hbase.sh
6、启动Spark
cd /usr/spark/spark-2.4.0-bin-hadoop2.7/sbin/
./start-all.sh
注:本文参考 https://blog.51cto.com/u_14691718/3333944 大佬的文章