python爬虫爬取知网数据(题名、作者、单位、关键字、摘要、来源、分类号、发表时间、数据库、下载地址)
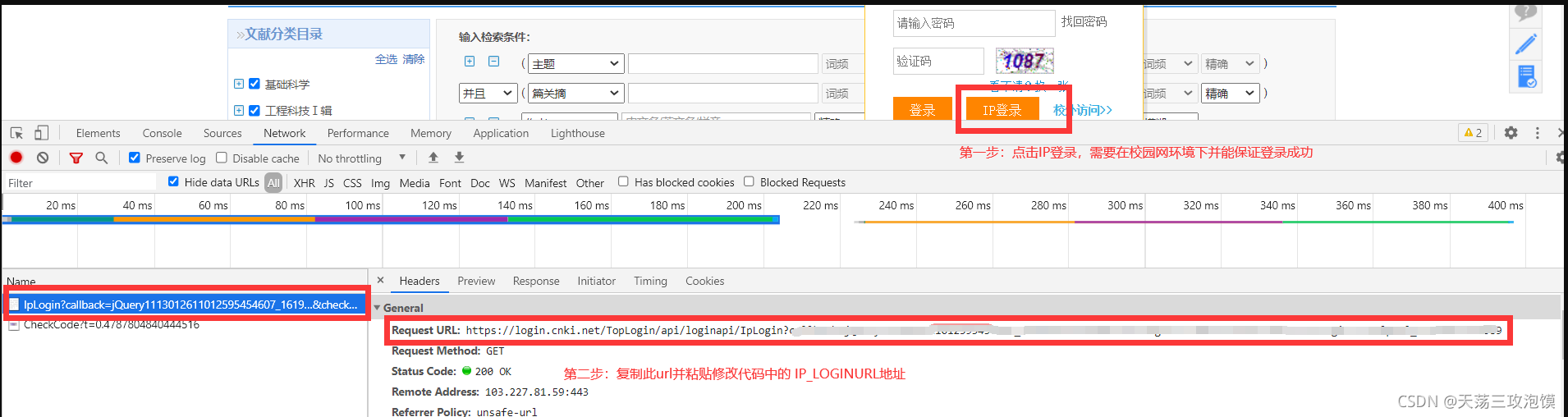
本章爬虫主要参考 GitHub - dgyy/CNKI-download: 知网(CNKI)文献下载及文献速览爬虫 大佬的github源码,但由于知网页面有些改动,再加上有些新增的需求,所以对代码有些许的改进,我自己改进的代码地址:GitHub - komorebi10086/python-spider: 爬虫-知网;其中有点麻烦的是需要下载caj的论文的话还需要去图书馆或者学校里面的账号进行ip登陆

1、首先没有安装pycharm的同伙们需要先安装pycharm,然后安装python3.5版本或者anaconda,这里我推荐安装anaconda,比较方便,网上谷歌或者百度官网下载安装就可以,很方便。
2、将git上的代码拉下来,电脑如果安装过git直接点击链接克隆到本地即可
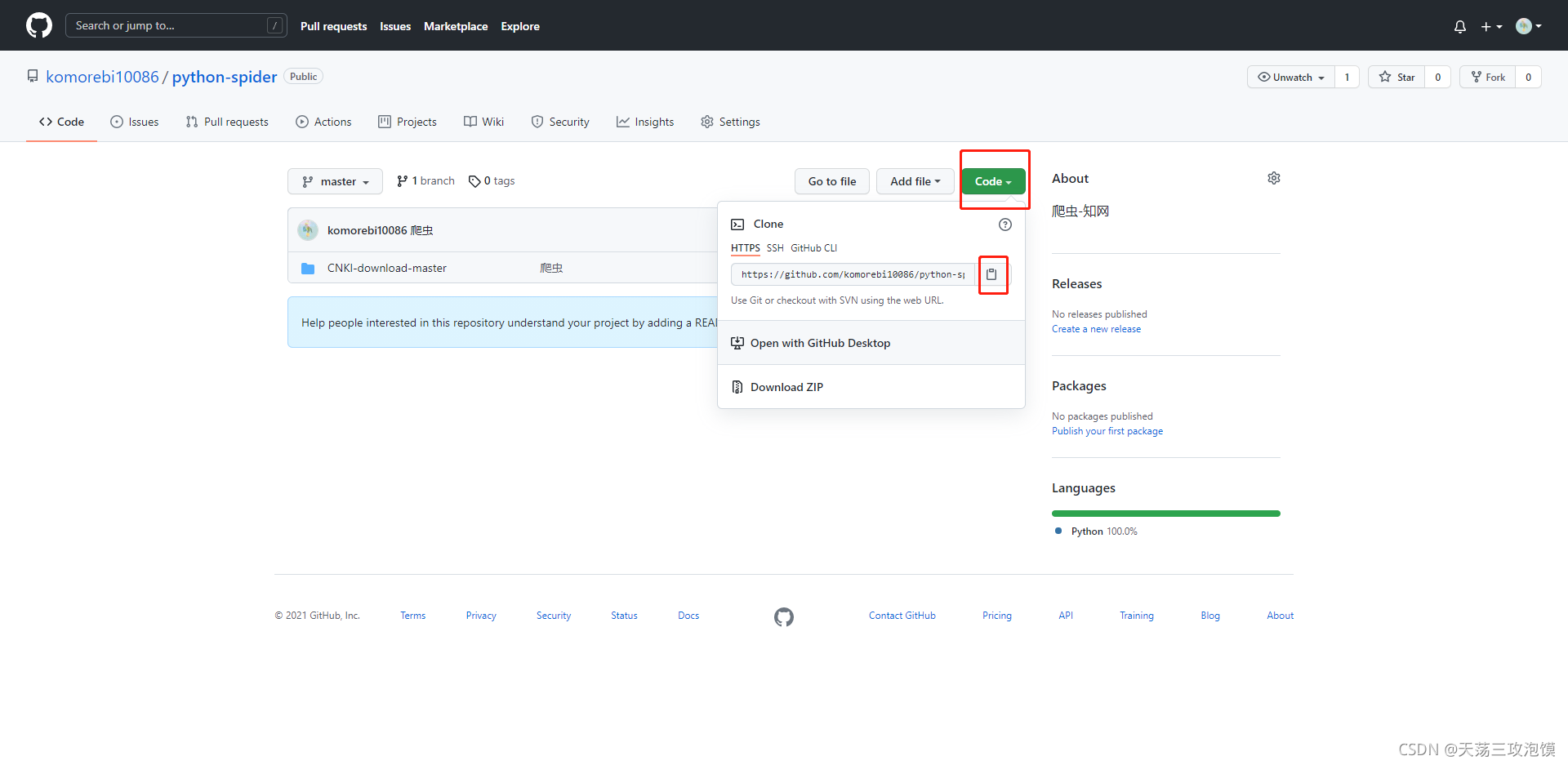
如果没有也可直接下载压缩包
3、接下来同伙们用pycharm打开文件夹,下载需要安装的库,可以在输入pip install XXX或者conda install XXX,后面的XXX是需要安装的库,哪里报红色的错安装哪里
4、然后需要我自己更改了两个地方,都是在爬取详情数据里面,第一部分是开启爬取详情数据之后爬取会报错,然后根据代码提示错误,更改了一部分代码:
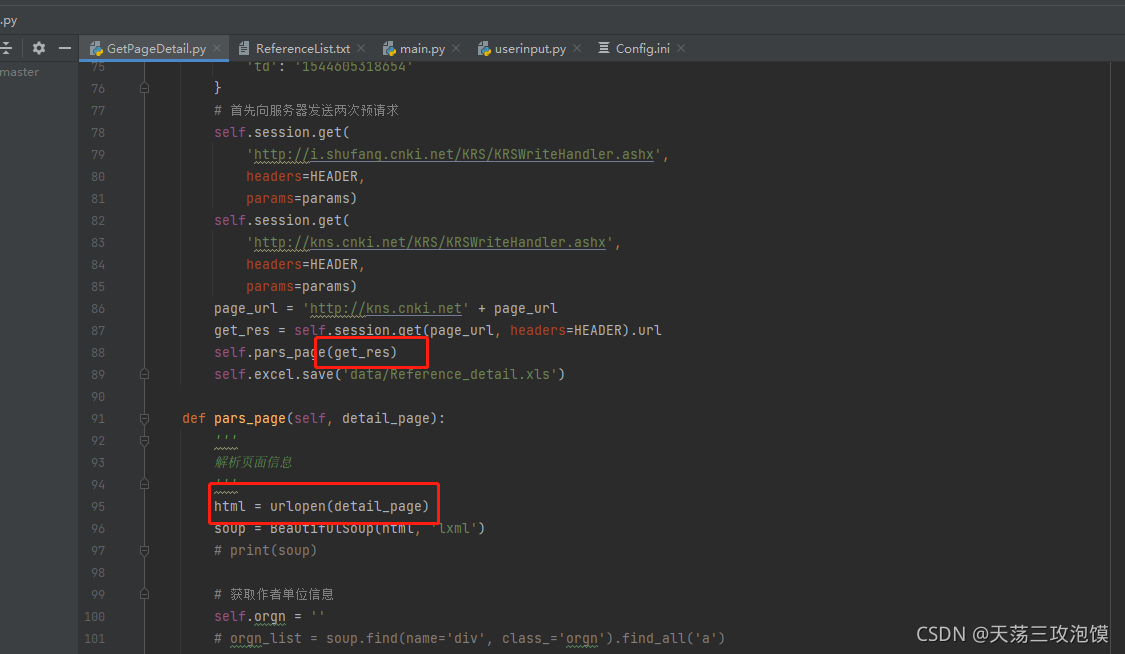
将GetPageDetel 中的get_detail_page函数里面,倒数第二行的.text,再再pars_page函数开头添加 一行 html = urlopen(detail_page) ,就可以爬取详细信息生成表格了。
5、由于需求增加,我们还需要爬取分类号,这里我是使用的xpath进行爬取;就在pars_page里面写下面的一行代码,用来获取分类号的信息。
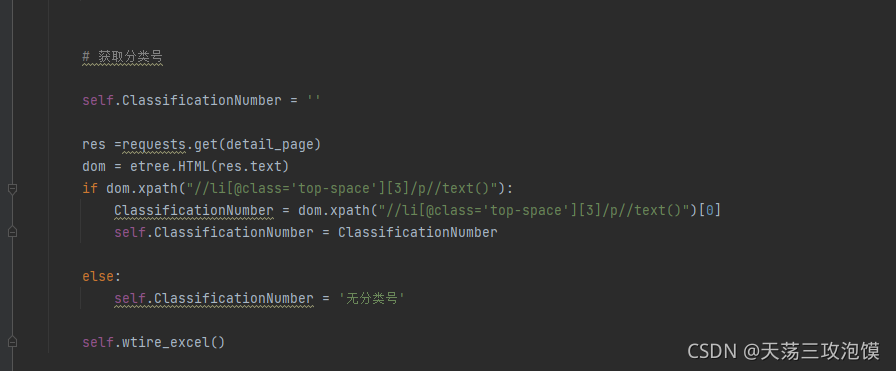
获取分类号信息之后,需要新增到excel里面,这里我就只在最上面新增了一句话即可
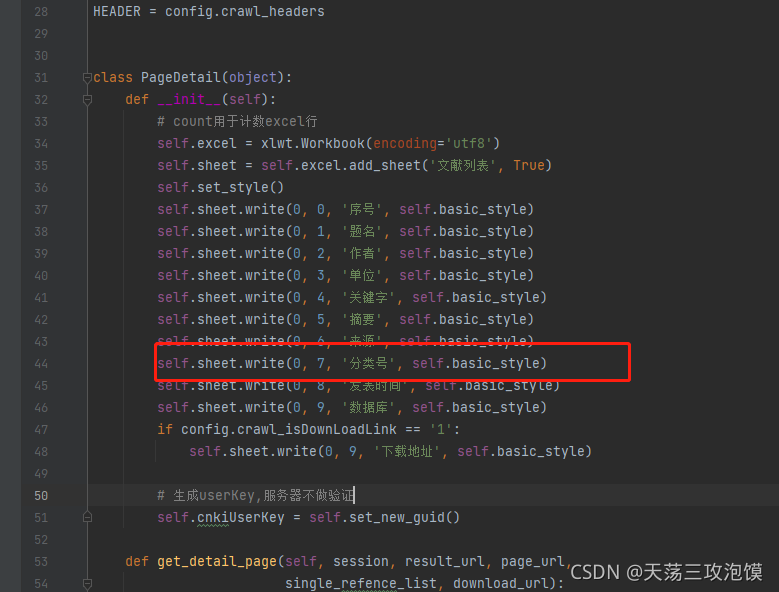
到这里更改的部分就几乎完成了,接下来就是运行的部分。直接点击运行,根据提示完成即可。